Summary: Introduction to AI/ML Toolkits with Kubeflow (LFS147)
Understanding Kubeflow
Kubeflow is an open-source machine learning toolkit designed to simplify the deployment, scaling, and management of ML workflows on Kubernetes. This article summarizes key concepts from the Linux Foundation’s Kubeflow course, focusing on its core components and how they support the model development lifecycle.
What is Kubeflow?
Kubeflow originated from Google’s internal approach to operating TensorFlow on Kubernetes. Initially offering a streamlined method for executing TensorFlow tasks, it has evolved into a comprehensive framework supported by multiple distributions across various cloud environments. In 2023, Google donated Kubeflow to the Cloud Native Computing Foundation (CNCF), ensuring it remains in neutral territory.
The name “Kubeflow” reflects its core purpose: running machine learning workflows (particularly TensorFlow initially) on Kubernetes, creating a fusion of “Kube” and “flow.”
Open Source vs. Open Core
Understanding Kubeflow’s position in the open source ecosystem is important:
- Open Source: Software where all code is freely available under permissive licenses, like Terraform’s initial release under MPL 2.0
- Open Core: A business model where core functionality is open source, but premium features are proprietary
- Integrated Open Source: Multiple open source projects integrated with custom code to create a cohesive solution
Kubeflow follows the integrated open source model, combining various open source tools into a comprehensive ML platform. The donation to the CNCF ensures it remains vendor-neutral, unlike cases like HashiCorp’s Terraform which changed from open source to a proprietary Business Source License.
Kubeflow Conformance
The Kubeflow community is developing conformance standards to:
- Define the core APIs and functionality that constitute “Kubeflow”
- Ensure interoperability between different distributions
- Provide certifications for distributions that meet these standards
- Enable more neutral deployment methods beyond vendor-specific distributions
This conformance program is part of Kubeflow’s graduation process within the CNCF and will help ensure consistency across implementations.
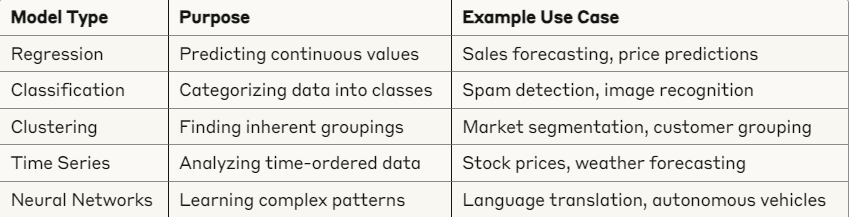
What is a Model?
A model is a computational entity that takes data as input and responds with a prediction based on learned patterns. Similar to how our brains connect new observations with existing knowledge, models process input data through patterns established during training.
Models can be of several types:
Model Features and Determinism
Features in machine learning are the specific attributes or indicators within datasets that help models recognize patterns. They’re like clues in a puzzle that the computer uses to learn. In deep learning, these features are often discovered by the network itself rather than being explicitly defined by humans.
Feature Stores like Feast (popular in the Kubeflow community) provide centralized locations where engineered features are stored, managed, and accessed. These stores ensure consistency in how features are used across different models and applications.
Determinism refers to the principle that a process will produce the same output for a given input every time. In ML, deterministic models will yield identical predictions for the same input data and will develop the same weights and biases if training is replicated with identical data and parameters. This property is crucial for reproducibility and debugging.
Containerization and Reproducibility
Containerization is vital for ML workflows as it:
- Ensures consistency across environments (“works on my machine” problems disappear)
- Improves security through verifiable builds (using hashing)
- Makes models more portable and deployable across different environments
- Facilitates reproducibility by capturing the exact environment in which a model runs
The serialization of models (converting models to storable formats) complements containerization by allowing models to be efficiently stored and deployed in a serverless pattern, similar to container deployment.
The Model Development Lifecycle
Kubeflow supports the entire model development lifecycle:

- Problem Definition & Scoping: Determining if a problem can be solved with data and establishing clear objectives
- Data Extraction: Accessing crucial data from various sources using ETL (Extract, Transform, Load) tools
- Data Analysis: Exploring datasets to understand features, identify patterns, and address data quality issues
- Data Preparation: Dividing datasets into training/validation/test sets, cleaning data, and engineering features
- Model Training: Using frameworks like TensorFlow or PyTorch to teach models to recognize patterns in data
- Model Serving: Exposing models through APIs or embedding them in applications for user access
- Model Monitoring: Tracking performance metrics, drift detection, and ensuring reliability in production
- Model Retirement: Properly decommissioning models and understanding the impact of removal
Kubeflow’s Core Mission
Kubeflow aims to bring DevOps concepts to machine learning through three key principles:
- Composability: Easily assembling and disassembling workflow components, allowing teams to select and integrate the best tools for specific stages of their ML development cycles
- Portability: Ensuring ML workflows are migratable and executable across environments, allowing development in one environment and deployment in another
- Scalability: Processing current work and dynamically allocating additional resources for new tasks, supporting both scaling up (more complex models) and scaling out (distributed training)
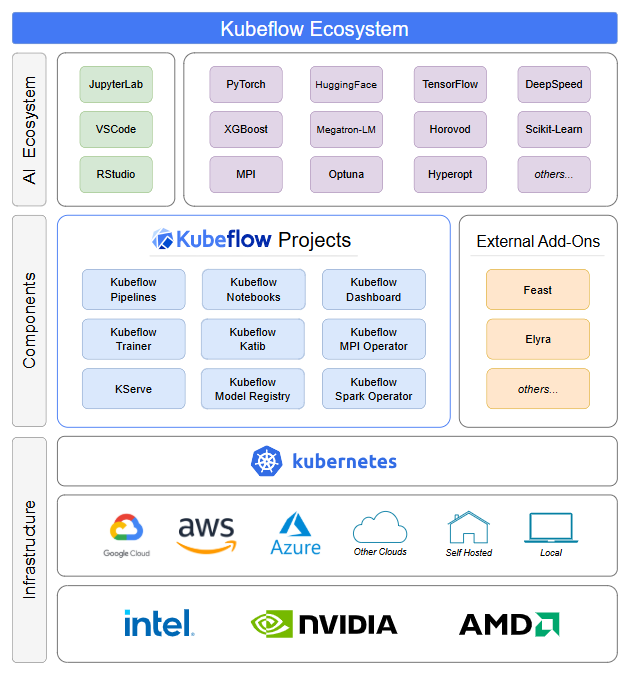
Image source: kubeflow.org
Kubeflow’s Key Components
1. Central Dashboard
A unified web interface that provides access to all Kubeflow services. The dashboard:
- Centralizes access to core services
- Enables namespace-based multi-tenancy
- Allows customization for specific organizational needs
- Integrates with Kubernetes RBAC and Istio for security
2. Kubeflow Notebooks
Provides integrated development environments (IDEs) as “Labs-as-a-Service” with benefits including:
- On-demand provisioning of customizable development environments
- Support for Jupyter, RStudio, and VS Code
- Resource isolation through Kubernetes namespaces
- Collaborative spaces for team members
- Integration with storage volumes for persistent work
- Automatic scaling and resource optimization
Limitations of Notebooks
While notebooks provide an excellent environment for experimentation, they have several limitations when used for production workloads:
Reliability Issues: Notebooks rely on a single pod, making them vulnerable to node failures. If the node requires maintenance or restarts, long-running jobs will be interrupted without automatic recovery.
Performance Constraints: Notebooks are limited to the resources of a single node, which can become a bottleneck for computationally intensive tasks. Training large models or processing big datasets may exceed single-node capacity.
Scaling Challenges: When multiple data scientists require high-resource notebooks, the cluster can quickly become saturated. Resource contention can lead to scheduling delays or prevent new notebooks from being created.
These limitations highlight why teams often need to transition from notebook-based development to more robust distributed training and pipeline solutions as projects mature.
3. Kubeflow Pipelines (KFP)
A workflow orchestration tool that enables defining and executing sequences of ML tasks as directed acyclic graphs (DAGs).
Component Types in Kubeflow Pipelines
KFP offers three types of components with different levels of flexibility and complexity:
Lightweight Python Components
- Description: Self-contained Python functions turned into pipeline steps
- Best for: Quick experimentation and prototyping
- Advantages:
- Fast iteration without container building
- Simple to create and modify
- Minimal setup required
- Limitations:
- All imports must be within the function body
- Limited to Python
- Packages are installed at runtime, affecting reproducibility and performance
- When to use: Early development phases, simple functions, rapid prototyping
Containerized Python Components
- Description: Python functions packaged as containers by the KFP SDK
- Best for: Production-ready Python code that needs external imports
- Advantages:
- Can use external modules and libraries
- Better reproducibility through containerization
- No need to be a container expert
- Limitations:
- Requires container registry access
- SDK dependency for building
- Still Python-only
- When to use: Production Python components, when code needs external dependencies
Container Components
- Description: Fully custom containers for maximum flexibility
- Best for: Complex components, non-Python code, specialized environments
- Advantages:
- Can use any programming language
- Complete control over the execution environment
- Maximum flexibility for complex tasks
- Limitations:
- Requires container expertise
- More complex to develop and maintain
- Needs careful handling of inputs and outputs
- When to use: Multi-language components, specialized processing needs, legacy code integration
Other Pipeline Features
- Runs: Individual executions of pipelines with specific parameters
- Experiments (KFP): Groups of related runs for comparison and organization
- Recurring Runs: Scheduled executions of pipelines at regular intervals
- Artifacts: Outputs produced by pipeline steps (datasets, models, metrics)
- Executions: Records of individual component runs within a pipeline
4. Katib for Automated Machine Learning
Katib is Kubeflow’s AutoML solution that automates hyperparameter tuning and neural architecture search.
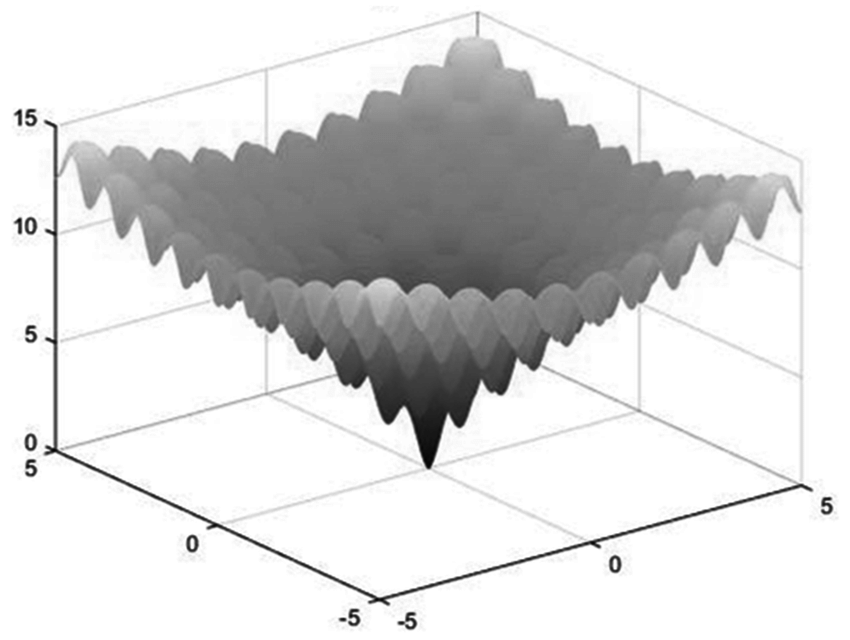
Finding Global Minima in Complex Optimization Landscapes
One of the key challenges in machine learning is finding the optimal set of hyperparameters in a high-dimensional space where many local minima exist. To understand this challenge, Katib uses test problems like the Ackley function – a mathematical function characterized by a large number of local minima surrounding one global minimum.
The Ackley function visualizes the problem faced in hyperparameter optimization: many “valleys” (local minima) that might trap simple optimization algorithms, while the true “deepest valley” (global minimum) is what we’re actually seeking.
In simpler terms:
- A local minimum is like a small dip in a hilly landscape – it’s lower than the immediate surrounding area, but not necessarily the lowest point overall.
- The global minimum is the absolute lowest point in the entire landscape – it represents the best possible solution across all possible configurations.
It’s called “global” because it’s the best solution across the entire search space, not just in a local region. This concept is crucial in machine learning because:
- Finding the global minimum means we’ve found the truly optimal hyperparameters that will give our model the best possible performance
- Most optimization algorithms tend to naturally fall into the nearest local minimum, potentially missing better solutions elsewhere
- The difference between a good local minimum and the global minimum can significantly impact model accuracy and reliability
In machine learning, the goal is to minimize errors or losses – hence the term “minimum” – and the “global” aspect ensures we’re finding the best solution possible rather than settling for a merely decent one.
Training Algorithms and Their Hyperparameters
Different algorithms require different hyperparameters to be tuned, and Katib can optimize these across various model types:
Gradient Descent-Based Algorithms
- Learning Rate: Controls the size of steps the algorithm takes towards the minimum of the loss function. Too large a learning rate can cause overshooting, while too small can lead to slow convergence.
- Momentum: Helps to accelerate the algorithm in the right direction, smoothing out updates.
- Batch Size: Influences the amount of data used to calculate each update, affecting the stability and speed of convergence.
Decision Tree-Based Algorithms
- Maximum Depth: Limits the depth of the tree to prevent overfitting.
- Minimum Samples Split: The minimum number of samples required to split an internal node.
- Maximum Number of Features: The number of features to consider when looking for the best split.
- Number of Layers and Units per Layer: Determines the neural network’s architecture, affecting its capacity to learn complex patterns.
- Activation Function: Influences how the weighted sum of the input is transformed before being passed to the next layer.
- Dropout Rate: A regularization technique that ignores randomly selected neurons during training, reducing overfitting.
Ensemble Methods (e.g., Random Forest, Gradient Boosting)
- Number of Estimators: The number of trees in the forest or the number of boosting stages.
- Learning Rate (for Boosting): Controls how much each additional tree contributes to the prediction.
- Max Features: The size of the random subsets of features to consider when splitting a node.
Experiments (AutoML)
Katib experiments are structured workflows to find optimal model configurations:
- Objective: The metric to optimize (e.g., accuracy, loss)
- Search Space: The range of hyperparameter values to explore
- Search Algorithm: The method to navigate the search space (random, grid, Bayesian)
- Trials: Individual model training runs with specific hyperparameter configurations
- Worker Jobs: The actual processes that execute trials, often using the Training Operator
Katib helps overcome the challenge of manually tuning hyperparameters, which can be time-consuming and computationally expensive. By automating this process, data scientists can focus on problem definition and feature engineering instead of parameter tweaking.
5. Training Operator
A framework-agnostic way to submit training jobs that:
- Simplifies job submissions through Kubernetes manifests
- Manages pod lifecycle and recovery from failures
- Handles the complexity of framework-specific distribution patterns
The Training Operator supports multiple frameworks with specialized capabilities:
TensorFlow Training (TFJob)
- Framework: TensorFlow, developed by Google
- Characteristics: Supports deployments with parameter servers and workers
- Distinctive Capabilities:
- Compatible with TPU (Tensor Processing Units)
- Complete ecosystem including TensorFlow Lite, TFX
- Optimized for large-scale distributed computing
- Supports both eager execution and graph execution
PyTorch Training (PyTorchJob)
- Framework: PyTorch, developed by Facebook AI Research
- Characteristics: Uses a dynamic computation approach
- Distinctive Capabilities:
- Dynamic computation graphs (can be modified on the fly)
- Highly Pythonic nature, easy to adopt
- Rich libraries: TorchVision, TorchText, TorchAudio
- User-friendly for prototyping and research
PaddlePaddle Training (PaddleJob)
- Framework: PaddlePaddle, developed by Baidu
- Characteristics: Industrial support and large-scale production focus
- Distinctive Capabilities:
- Specialized tools like Paddle Lite for mobile devices
- Optimized support for Baidu’s Kunlun chips
- High-level APIs to simplify development
- Strong support for natural language processing and computer vision
MXNet Training (MXJob)
- Framework: Apache MXNet, supported by AWS
- Characteristics: Hybrid programming model
- Distinctive Capabilities:
- Combines symbolic and imperative programming via the Gluon API
- Support for multiple programming languages (Scala, C++, R, JavaScript)
- Optimized for memory efficiency and speed
- ONNX support for model portability
XGBoost Training (XGBoostJob)
- Framework: XGBoost (eXtreme Gradient Boosting)
- Characteristics: Specializes in gradient boosting algorithms
- Distinctive Capabilities:
- Excellent handling of sparse data
- Built-in L1 and L2 regularization
- Ability to run on various languages and platforms
- Optimized tree pruning
- Built-in cross-validation
MPI Training (MPIJob)
- Framework: Message Passing Interface, a standard for process communication
- Characteristics: Facilitates “allreduce” style distributed training
- Distinctive Capabilities:
- Enables efficient communication between different processes
- Optimizes network usage for distributed models
- Eliminates the need to configure the optimal ratio between workers and parameter servers
- Ideal for high-performance computing (HPC)
- Interoperable with multiple ML frameworks
6. Model Registry Integration
While not a core Kubeflow component, model registries like MLflow are commonly integrated with Kubeflow to:
- Catalog and version models
- Track model lineage and metadata
- Facilitate deployment from artifact storage
- Manage the model lifecycle from experimentation to production
Model registries complement Kubeflow’s focus on workflow orchestration by providing specialized tools for model management and governance.
Kubernetes Scheduler Limitations and Volcano
Standard Kubernetes Scheduler Limitations
The default Kubernetes scheduler has several limitations for ML workloads:
Single-Pod Scheduling: The scheduler processes one pod at a time without considering relationships between pods in a distributed job.
Resource Fragmentation: Without awareness of pod groups, resources can become fragmented, leading to situations where no single node has enough resources for a pod, even though the collective cluster has sufficient capacity.
No Coordination: For distributed training jobs that require all components to start simultaneously, the default scheduler provides no guarantees that all pods will be scheduled together.
Limited Hardware Awareness: The standard scheduler has limited understanding of specialized hardware topologies, which can lead to suboptimal placement of ML workloads.
Gang Scheduling with Volcano
Gang scheduling is a batch scheduling approach where a group of related tasks (a “gang”) are scheduled to run simultaneously. Volcano implements this concept for Kubernetes:
- All-or-Nothing Scheduling: Either all pods in a job are scheduled, or none are, preventing partial job execution and resource waste
- Queue Management: Jobs can be prioritized and placed in queues when resources are unavailable, avoiding gridlock
- Hardware Topology Awareness: Optimizes placement based on node interconnects and hardware specifics
- Resource Fairness: Ensures equitable resource distribution across teams and workloads
Consider a distributed TensorFlow job with 1 parameter server and 4 workers. With the default scheduler, some pods might get scheduled while others remain pending due to resource constraints. The scheduled pods would consume resources while waiting indefinitely for their counterparts. Volcano ensures that either all 5 pods get scheduled together, or the job waits in a queue until sufficient resources are available.
Common Kubeflow Integrations
Kserve
A serverless model inference platform that:
- Deploys models without requiring custom servers
- Supports major frameworks (TensorFlow, PyTorch, ONNX, etc.)
- Handles auto-scaling based on demand (scale to zero when idle)
- Provides built-in model versioning and canary deployments
- Manages preprocessing, prediction, post-processing, and monitoring
- Implements A/B testing and progressive model rollouts
Kserve abstracts away the complexities that teams previously had to handle manually with custom Flask or FastAPI implementations, including model loading, API endpoints, data preprocessing, concurrency, and security.
Volcano
A batch scheduling system for high-performance workloads that:
- Implements gang scheduling to ensure all related pods start together
- Prevents gridlock by considering total resource requirements
- Optimizes for specific hardware like GPUs and specialized accelerators
- Supports job prioritization and fair-sharing through queues
- Considers network topology for optimized placement
Advantages of Kubeflow
- Framework Flexibility: Supports multiple ML frameworks and allows teams to use the right tool for each job
- Resource Optimization: Efficiently allocates computational resources, particularly for expensive GPU workloads
- Workflow Automation: Reduces manual intervention through standardized pipelines and components
- Reproducibility: Ensures consistent results through containerization and version control
- Collaboration: Enables team members to share work, models, and results through a unified platform
- Security: Integrates with Kubernetes RBAC and network policies for proper isolation
- Scalability: Handles workloads from small experiments to production-grade deployment
Distributions and Deployment
Kubeflow can be deployed through several approaches:
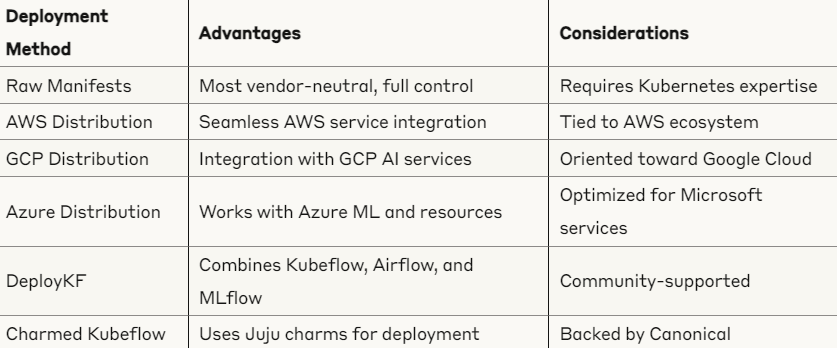
The future development of conformance standards will likely lead to more vendor-neutral deployment options, similar to how Kubernetes evolved from “the hard way” to more standardized deployment methods.


![Understanding Karpenter’s Node Consolidation [EKS]: A Deep Dive](https://devopsmotion.com/wp-content/uploads/2024/12/1589294377f_-x_b_w_david_reckert-768x1024.jpg)