Monitoring Kubernetes with Popeye, Prometheus & Grafana
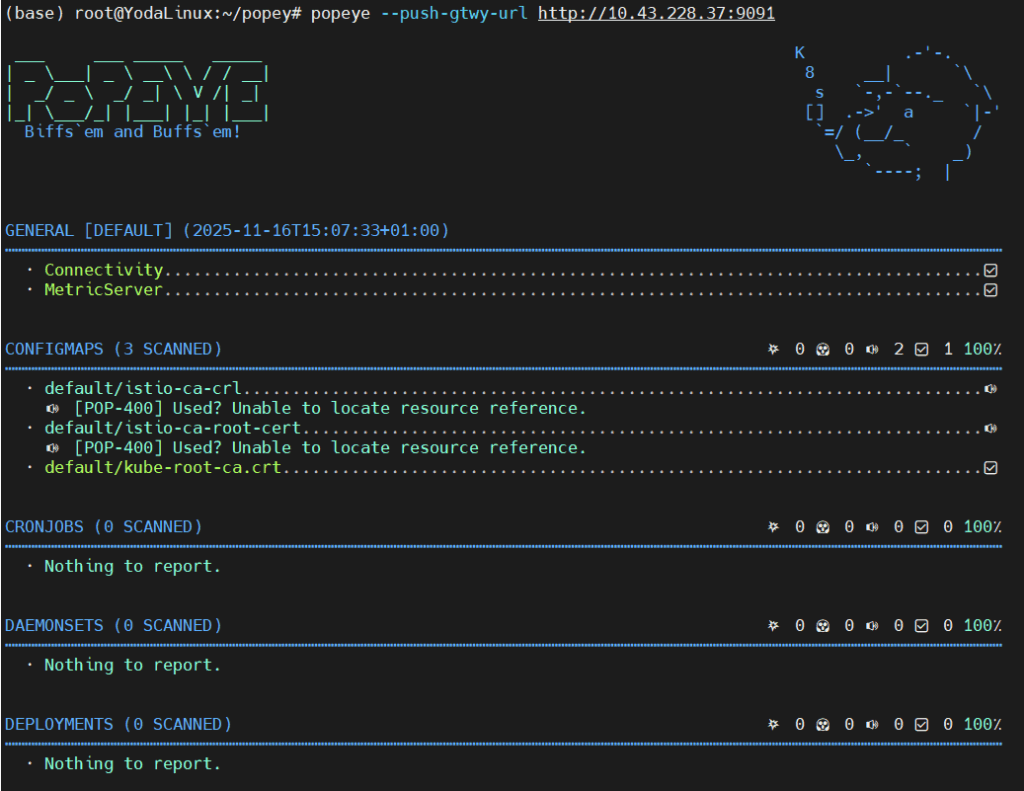


Popeye is a utility that scans live Kubernetes clusters and reports potential issues with deployed resources and configurations.
I set up Popeye to scan my K3s cluster and visualize results in Grafana using Pushgateway. Total setup time: ~30 minutes.
There are multiple ways to install Popeye (binary, Docker, Homebrew). Check the official Popeye GitHub for all options.
I went with the Debian package:
wget https://github.com/derailed/popeye/releases/download/v0.22.1/popeye_linux_amd64.deb
dpkg -i popeye_linux_amd64.deb
mv popeye /usr/local/bin/
chmod +x /usr/local/bin/popeyeCreated a simple deployment:
Note:
Pushgateway = Temporary storage for metrics from short-lived jobs
The Problem:
Prometheus pulls (scrapes) metrics from targets. But what if your job finishes before Prometheus can scrape it?
Pushgateway acts as a buffer:
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus-pushgateway
namespace: monitoring
spec:
replicas: 1
selector:
matchLabels:
app: pushgateway
template:
metadata:
labels:
app: pushgateway
spec:
containers:
- name: pushgateway
image: prom/pushgateway:v1.9.0
ports:
- containerPort: 9091
---
apiVersion: v1
kind: Service
metadata:
name: prometheus-pushgateway
namespace: monitoring
labels:
app: pushgateway
spec:
type: ClusterIP
ports:
- port: 9091
targetPort: 9091
selector:
app: pushgateway
---
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: pushgateway
namespace: monitoring
labels:
app: pushgateway
spec:
selector:
matchLabels:
app: pushgateway
endpoints:
- port: http
interval: 30s
honorLabels: trueApplied with:
kubectl apply -f pushgateway-deployment.yamlSince I have a K3s setup, I am allowed direct ClusterIP access (I am already on the K3S node).
kubectl get svc -n monitoring prometheus-pushgateway
# prometheus-pushgateway ClusterIP 10.43.228.37 <none> 9091/TCP
curl http://10.43.228.37:9091/-/healthy
# OKCritical step: Ensure the Service has the correct label for the ServiceMonitor to match:
ServiceMonitor uses selector (filtre) to find the service it needs to scrap
(base) root@YodaLinux:~# kubectl get svc prometheus-pushgateway -n monitoring --show-labels
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE LABELS
prometheus-pushgateway ClusterIP 10.43.228.37 <none> 9091/TCP 2d9h app=pushgateway
ServiceMonitor:
selector:
matchLabels:
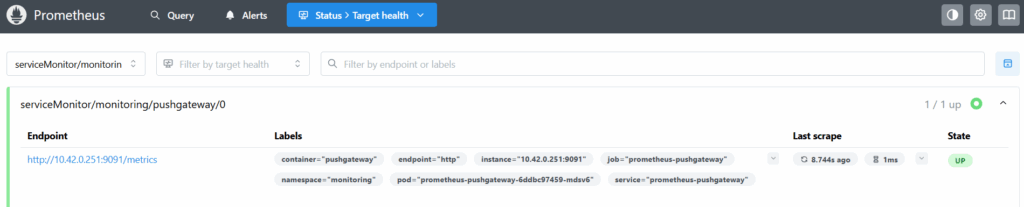
app: pushgateway popeye --push-gtwy-url http://10.43.228.37:9091Status > Targets → pushgateway status: UP
Tested few Promql queries (optional):
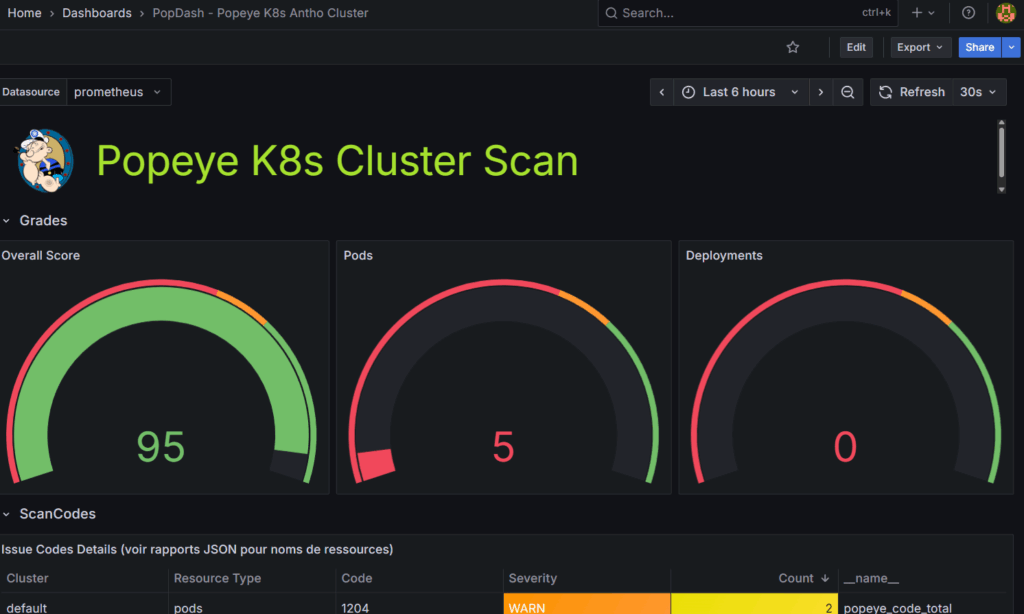
I used Claude (Sonnet 4.5) to create a custom dashboard which almost matched the official Popeye dashboard style (I could not find the dashboard). The dashboard includes:
You can find my dashboard here: https://github.com/cuspofaries/popey-grafana-dashboard/blob/main/popey-grafana-dashboard-fr
Import the JSON in Grafana: Dashboards >New > Import > Upload JSON
The dashboard auto-refreshes every 30 seconds.
Added to crontab:
# Scan every 30 minutes
*/30 * * * * popeye --push-gtwy-url http://10.43.228.37:9091Create PrometheusRule for basic alerts:
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: popeye-alerts
namespace: monitoring
spec:
groups:
- name: popeye.rules
interval: 5m
rules:
- alert: PopeyeClusterScoreLow
expr: popeye_cluster_score < 60
for: 15m
labels:
severity: warning
annotations:
summary: "Cluster score below 60"
- alert: PopeyeTooManyErrors
expr: popeye_report_errors_total > 10
for: 10m
labels:
severity: critical
annotations:
summary: "Too many errors detected"
Migrate a MySQL Database from Docker to Kubernetes Not long ago, I had to migrate an application from Docker to Kubernetes. As part of this process, I needed to move the MySQL 8.0.39 database from a Docker container to a Kubernetes cluster. I thought it could be interesting to share how I accomplished this task,…
Understanding Kubeflow Kubeflow is an open-source machine learning toolkit designed to simplify the deployment, scaling, and management of ML workflows on Kubernetes. This article summarizes key concepts from the Linux Foundation’s Kubeflow course, focusing on its core components and how they support the model development lifecycle. What is Kubeflow? Kubeflow originated from Google’s internal approach…
![Understanding Karpenter’s Node Consolidation [EKS]: A Deep Dive](https://devopsmotion.com/wp-content/uploads/2024/12/1589294377f_-x_b_w_david_reckert-768x1024.jpg)
This article assumes you have already installed karpenter and it’s intent is only to describe some caveat about consolidation mechanisms especially spot-to-spot consolidation in an EKS Cluster. As we will see, spot-to-spot consolidation ain’t an out of the box functionality and there are few things to be aware of if you want it to work…